83 lines
4.7 KiB
Markdown
83 lines
4.7 KiB
Markdown
# vWeChatCrawl-小V公众号文章下载(开源版)
|
||
批量导出任意微信公众号历史文章,会用python写hello world就会用这个。
|
||
# 注意:
|
||
github在国内访问有时很缓慢,特别是图片,我把本说明文档同步放到了我的[个人博客](https://www.xiaokuake.com/p/?p=1102&preview=true)
|
||
项目中用到的wkhtmltopdf如果从github下载慢也可以[点此下载](http://www.xiaokuake.com/p/wp-content/uploads/2019/08/2019080810033092.rar)后把wkhtmltopdf复制到本项目的目录下。
|
||
|
||
本项目的最新文章会发在公众号“不止技术流”中,欢迎关注。
|
||

|
||
QQ交流群 703431832 加群暗号"不止技术流"
|
||
|
||
# 使用步骤:
|
||
## a.安装Python库
|
||
直接 python setupPackage.py 安装本项目需要的库。有朋友反映默认源安装慢,这里我用了豆瓣的源。
|
||
## b.安装并配置Fiddler
|
||
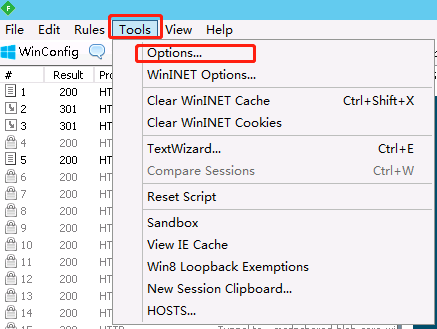
Fiddler的官网有时会连不上,可去pc.qq.com搜索Fiddler4 并安装
|
||
|
||
|
||
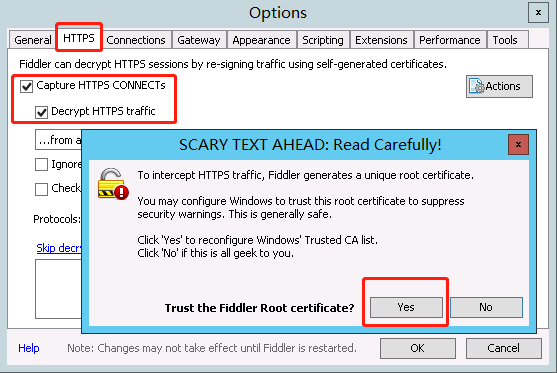
会弹出几个窗口,都点 Yes
|
||
|
||
|
||
|
||
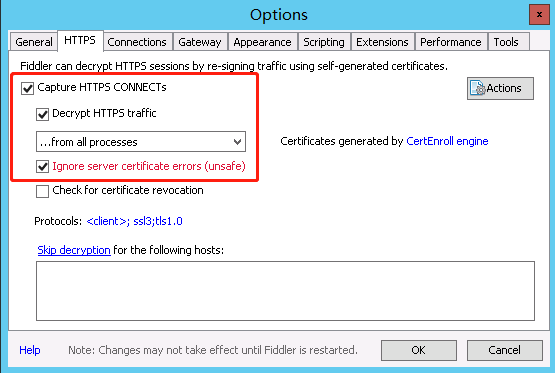
最后是这样的,打了 3 个钩。点 OK 保存即可。
|
||
|
||
|
||
|
||
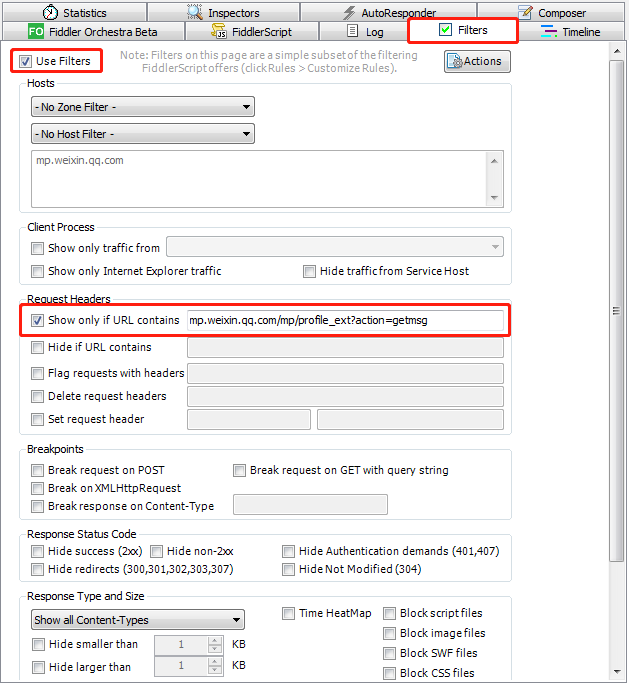
在主窗口右侧按下图所示设置,其中需要填的网址为 mp.weixin.qq.com/mp/profile_ext?action=getms
|
||
|
||
|
||
|
||
|
||
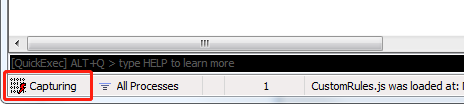
至此配置完成了,点软件左下角的方块,会显示Capturing ,表示它此时处在可以抓取数据的状态,再点一下会暂停抓取。此处先打开为抓取状态
|
||
|
||
|
||
有的朋友可能会在Fiddler 中抓取不到Https请求,请仔细按照上面流程检查。若有其他异常,绝大多数Fiddler相关的问题通过百度可以解决。
|
||
|
||
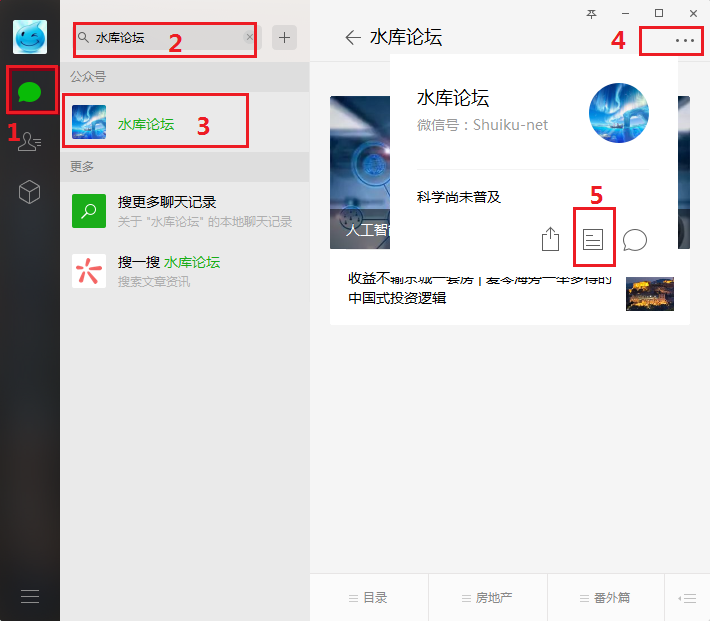
## c.打开某个微信公众号的历史文章列表
|
||
|
||
|
||
不断下划,使历史文章列表都显示出来,但注意不要划得太快。
|
||
|
||
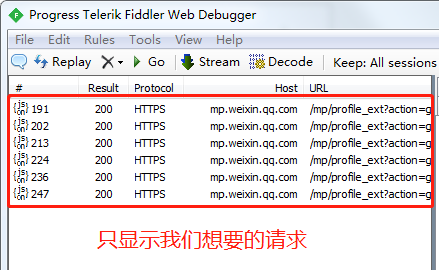
Fiddler中显示了我们需要的请求
|
||
|
||
|
||
|
||
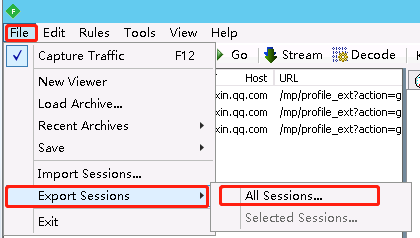
把这些请求保存下来,基中包含文章url列表
|
||
|
||
|
||
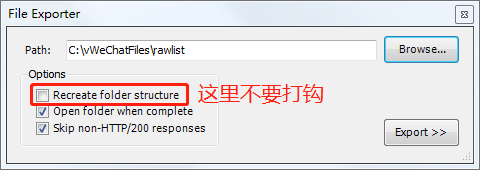
|
||
|
||
## d.运行python文件
|
||
打开本项目的 config.json 文件,设置
|
||
- jsonDir:上面在Fiddler中保存的文件
|
||
- htmlDir:保存html的目录,路径中不能有空格
|
||
- pdfDir:保存pdf的目录,路径中不能有空格
|
||
改完记得保存文件
|
||
|
||
|
||
|
||
运行 python start.py #开始下载html
|
||
运行 python start.py pdf #把下载的html转pdf
|
||
|
||
上文中没提到的文件是实现其他功能的(作者偷懒把好几个项目都放在了这里),感兴趣的可了解,不感兴趣的也并不影响使用你使用上文所述的功能。
|
||
|
||
## 补充
|
||
|
||
我还开发了一个全功能版,集成了数据分析功能,可免费试用 [https://www.xiaokuake.com](https://www.xiaokuake.com?id=github)
|
||
|
||
作者微信 kakaLongcn 有其他公众号相关功能/爬虫定制需求的可一起讨论
|
||
|
||
本开源项目仅用于技术学习交流,请勿用于非法用途,由此引起的后果本作者概不负责。
|
||
|
||
|
||
主要思路参考这几篇文章
|
||
[一步步教你打造文章爬虫(1)-综述](https://mp.weixin.qq.com/s?__biz=MzAxMDM4MTA2MA==&mid=2455304602&idx=1&sn=4beadc781c44c17cb4451b579d077c45&chksm=8cfd6bf1bb8ae2e7d5a9f1a66696dd12e260ac7919c7bebe317af81e90bd25591ba286da1f0f&token=2137480545&lang=zh_CN#rd)
|
||
[一步步教你打造文章爬虫(2)-下载网页](https://mp.weixin.qq.com/s?__biz=MzAxMDM4MTA2MA==&mid=2455304609&idx=1&sn=b7496563aab42e92060bd68936bc4212&chksm=8cfd6bcabb8ae2dc606b060fecf3f837177e3ef22a05a30ee28ebefd75c6677b29df3e426692&token=2137480545&lang=zh_CN#rd)
|
||
特别要仔细看第3篇
|
||
[一步步教你打造文章爬虫(3)-批量下载
|
||
](https://mp.weixin.qq.com/s?__biz=MzAxMDM4MTA2MA==&mid=2455304632&idx=1&sn=d0a1f6ef7e5d4356d17219a2b79f65d4&chksm=8cfd6bd3bb8ae2c532f901e11aa4b080c19f16626f0dceb291fcb8270e2d7689d7b97d232683&token=2137480545&lang=zh_CN#rd)
|
||
|
||
#其他接口:
|
||
实时推送公众号最新文章列表,即用户发送post请求,传入公众号列表,服务器返回相应的公众号文章链接、标题、发布时间等列表。详情查看项目中的 fetchNewArticle.py文件。
|
||
|