优化文件路径易出错的问题,美化下载进度条
This commit is contained in:
@@ -31,6 +31,8 @@ Fiddler的官网有时会连不上,可去pc.qq.com搜索Fiddler4 并安装
|
||||
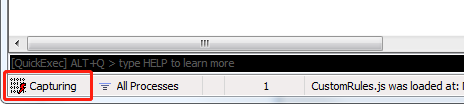
至此配置完成了,点软件左下角的方块,会显示Capturing ,表示它此时处在可以抓取数据的状态,再点一下会暂停抓取。此处先打开为抓取状态
|
||||
|
||||
|
||||
有的朋友可能会在Fiddler 中抓取不到Https请求,请仔细按照上面流程检查。若有其他异常,绝大多数Fiddler相关的问题通过百度可以解决。
|
||||
|
||||
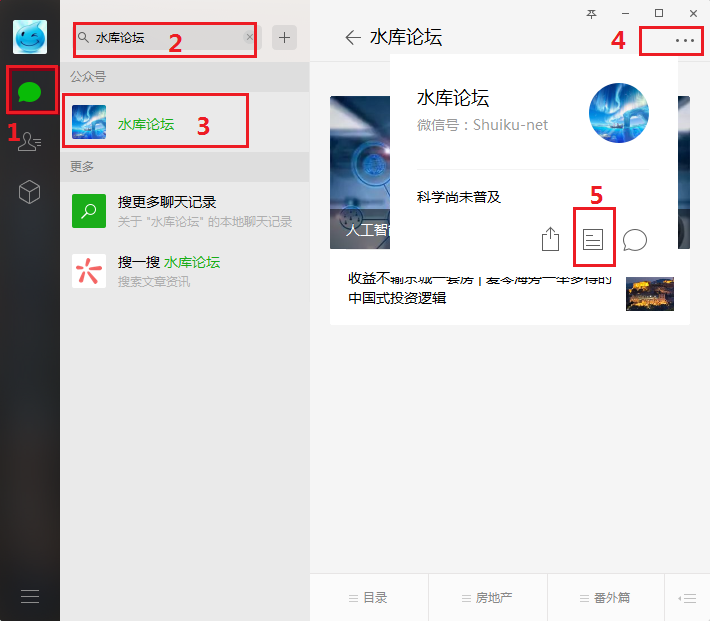
## c.打开某个微信公众号的历史文章列表
|
||||
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
{
|
||||
"jsonDir": "C:/Users/kklwin10/Desktop/Dump-0103-20-14-29",
|
||||
"htmlDir": "c:/vWeChatFiles/html/",
|
||||
"pdfDir": "c:/vWeChatFiles/pdf/"
|
||||
"jsonDir": "c:/Users/kklwin10/Desktop/Dump-0103-20-14-29",
|
||||
"htmlDir": "c:/vWeChatFiles/html",
|
||||
"pdfDir": "c:/vWeChatFiles/pdf"
|
||||
}
|
||||
42
start.py
42
start.py
@@ -8,6 +8,7 @@ from time import sleep
|
||||
|
||||
"""
|
||||
本项目开源地址 https://github.com/LeLe86/vWeChatCrawl
|
||||
讨论QQ群 703431832
|
||||
|
||||
"""
|
||||
|
||||
@@ -34,6 +35,10 @@ def GetJson():
|
||||
jstxt = ReadFile("config.json")
|
||||
jstxt = jstxt.replace("\\\\","/").replace("\\","/") #防止json中有 / 导致无法识别
|
||||
jsbd = json.loads(jstxt)
|
||||
if jsbd["htmlDir"][-1]=="/":
|
||||
jsbd["htmlDir"] = jsbd["htmlDir"][:-1]
|
||||
if jsbd["jsonDir"][-1]=="/":
|
||||
jsbd["jsonDir"]= jsbd["jsonDir"][:-1]
|
||||
return jsbd
|
||||
|
||||
|
||||
@@ -46,8 +51,8 @@ def DownLoadHtml(url):
|
||||
'Connection':'keep-alive',
|
||||
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3'
|
||||
}
|
||||
|
||||
response = requests.get(url,headers = headers,proxies=None)
|
||||
requests.packages.urllib3.disable_warnings()
|
||||
response = requests.get(url,headers = headers,proxies=None,verify=False)
|
||||
if response.status_code == 200:
|
||||
htmltxt = response.text #返回的网页正文
|
||||
return htmltxt
|
||||
@@ -63,7 +68,8 @@ def DownImg(url,savepath):
|
||||
'Connection':'keep-alive',
|
||||
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3'
|
||||
}
|
||||
r = requests.get(url,headers = headers,proxies=None)
|
||||
requests.packages.urllib3.disable_warnings()
|
||||
r = requests.get(url,headers = headers,proxies=None,verify=False)
|
||||
with open(savepath, 'wb') as f:
|
||||
f.write(r.content)
|
||||
|
||||
@@ -84,7 +90,7 @@ def ChangeImgSrc(htmltxt,saveimgdir,htmlname):
|
||||
if originalURL.startswith("//"):#如果url以//开头,则需要添加http:
|
||||
originalURL = "http:" + originalURL
|
||||
if len(originalURL) > 0:
|
||||
print("down img",imgindex)
|
||||
print("\r down imgs " + "▇" * imgindex +" " + str(imgindex),end="")
|
||||
if "data-type" in img.attrs:
|
||||
imgtype = img.attrs["data-type"]
|
||||
else:
|
||||
@@ -109,7 +115,10 @@ def ChangeCssSrc(bs):
|
||||
|
||||
def ChangeContent(bs):
|
||||
jscontent = bs.find(id="js_content")
|
||||
jscontent.attrs["style"]=""
|
||||
if jscontent:
|
||||
jscontent.attrs["style"]=""
|
||||
else:
|
||||
print("-----可能文章被删了-----")
|
||||
|
||||
#文章类
|
||||
class Article():
|
||||
@@ -142,7 +151,8 @@ def GetArticleList(jsondir):
|
||||
idx = artidx
|
||||
title = app_msg_ext_info["title"]
|
||||
art = Article(url,pubdate,idx,title)
|
||||
ArtList.append(art)
|
||||
if len(url)>3:#url不完整则跳过
|
||||
ArtList.append(art)
|
||||
print(len(ArtList),pubdate, idx, title)
|
||||
if app_msg_ext_info["is_multi"] == 1: # 一次发多篇
|
||||
artidx += 1
|
||||
@@ -152,7 +162,8 @@ def GetArticleList(jsondir):
|
||||
idx =artidx
|
||||
title = subArt["title"]
|
||||
art = Article(url,pubdate,idx,title)
|
||||
ArtList.append(art)
|
||||
if len(url)>3:
|
||||
ArtList.append(art)
|
||||
print(len(ArtList),pubdate, idx, title)
|
||||
return ArtList
|
||||
|
||||
@@ -160,7 +171,7 @@ def DownHtmlMain(jsonDir,saveHtmlDir):
|
||||
saveHtmlDir = jsbd["htmlDir"]
|
||||
if not os.path.exists(saveHtmlDir):
|
||||
os.makedirs(saveHtmlDir)
|
||||
saveImgDir = os.path.join(saveHtmlDir, "images")
|
||||
saveImgDir = saveHtmlDir+ "/images"
|
||||
if not os.path.exists(saveImgDir):
|
||||
os.makedirs(saveImgDir)
|
||||
ArtList = GetArticleList(jsonDir)
|
||||
@@ -171,7 +182,7 @@ def DownHtmlMain(jsonDir,saveHtmlDir):
|
||||
idx+=1
|
||||
artname = art.pubdate + "_" + str(art.idx)
|
||||
arthtmlname = artname + ".html"
|
||||
arthtmlsavepath = os.path.join(saveHtmlDir,arthtmlname)
|
||||
arthtmlsavepath = saveHtmlDir+"/"+arthtmlname
|
||||
print(idx,"of",totalCount,artname,art.title)
|
||||
# 如果已经有了则跳过,便于暂停后续传
|
||||
if os.path.exists(arthtmlsavepath):
|
||||
@@ -179,6 +190,7 @@ def DownHtmlMain(jsonDir,saveHtmlDir):
|
||||
continue
|
||||
arthtmlstr = DownLoadHtml(art.url)
|
||||
arthtmlstr = ChangeImgSrc(arthtmlstr,saveImgDir,artname)
|
||||
print("\r",end="")
|
||||
SaveFile(arthtmlsavepath,arthtmlstr)
|
||||
|
||||
sleep(3) #防止下载过快被微信屏蔽,间隔3秒下载一篇
|
||||
@@ -191,7 +203,7 @@ def PDFDir(htmldir,pdfdir):
|
||||
for f in flist:
|
||||
if (not f[-5:]==".html") or ("tmp" in f): #不是html文件的不转换,含有tmp的不转换
|
||||
continue
|
||||
htmlpath = os.path.join(htmldir,f)
|
||||
htmlpath = htmldir+"/"+f
|
||||
tmppath = htmlpath[:-5] + "_tmp.html"#生成临时文件,供转pdf用
|
||||
htmlstr = ReadFile(htmlpath)
|
||||
bs = BeautifulSoup(htmlstr, "lxml")
|
||||
@@ -201,8 +213,8 @@ def PDFDir(htmldir,pdfdir):
|
||||
if titleTag is not None:
|
||||
title = "_" + titleTag.get_text().replace(" ", "").replace(" ","").replace("\n","")
|
||||
ridx = htmlpath.rindex("/") + 1
|
||||
htmlname = htmlpath[ridx:-5] + title
|
||||
pdfpath = os.path.join(pdfdir, htmlname + ".pdf")
|
||||
pdfname = htmlpath[ridx:-5] + title
|
||||
pdfpath = pdfdir+"/"+ pdfname + ".pdf"
|
||||
|
||||
"""
|
||||
把js等去掉,减少转PDF时的加载项,
|
||||
@@ -236,10 +248,14 @@ def PDFOne(htmlpath,pdfpath,skipExists=True,removehtml=True):
|
||||
|
||||
|
||||
"""
|
||||
先去config.json文件设置
|
||||
1.设置:
|
||||
先去config.json文件中设置
|
||||
jsonDir:Fiddler生成的文件
|
||||
htmlDir:保存html的目录,路径中不能有空格
|
||||
pdfDir:保存pdf的目录,路径中不能有空格
|
||||
2.使用方法:
|
||||
运行 python start.py #开始下载html
|
||||
运行 python start.py pdf #把下载的html转pdf
|
||||
"""
|
||||
if __name__ == "__main__":
|
||||
if len(sys.argv)==1:
|
||||
|
||||
Reference in New Issue
Block a user